What is Generative Intelligence?
Generative intelligence pairs human perception and decision making capabilities of artificial intelligence (AI) with the scientific disciplines of dynamic complexity and perturbation theory, supported by causal deconstruction, to create a systemic and iterative collection of rational and unbiased knowledge that exceeds human intelligence.
Through the applied use of generative intelligence, it becomes possible for machines to automatically monitor an environment and take action to maximize the chance of successfully achieving a set of defined goals. Generative intelligence covers both known patterns, as well as new, unknown patterns that are exposed through mathematical emulation, and may be discovered through sensitivity analysis and stress testing.
The Expansion of Human Intelligence
Ray Kurzweil envisions a future where, “vastly expanded human intelligence (predominantly non biological) spreads through the universe.” To make this future a reality, we need to expand our definition of AI and our means of understanding and creating intelligence.
Despite recent advancements in artificial intelligences, there are still many things humans can easily do, but smart machines cannot. For instance, new situations baffle artificial intelligences because the deep learning they depend upon uses mainly statistical methods to classify patterns using neural networks.
Neural networks memorize classes of things and in most circumstances know when they encounter them again. To expand the capabilities of AI, people have added more layers and more data to neural networks in an attempt to replicate human intelligence. But pattern recognition (exercised on existing structures) alone can never match the cognitive capabilities of humans and its continuous evolution.
As a result, artificial intelligences fail when they encounter an unknown. Pedro Domingos, the author of The Master Algorithm and a professor of computer science at the University of Washington explains, “A self-driving car can drive millions of miles, but it will eventually encounter something new for which it has no experience.”
Gary Marcus, a professor of cognitive psychology at NYU makes clear the gap between human and artificial intelligences, stating, “We are born knowing there are causal relationships in the world, that wholes can be made of parts, and that the world consists of places and objects that persist in space and time. No machine ever learned any of that stuff using backprop[1].”
To match or even exceed the cognitive capabilities of the human brain, it will be important to employ reliable methods that allow machines to map the causal relationship of dynamically complex systems, uncover the factors that will lead to a system singularity[2] and identify the necessary solutions before the event occurs.
Filling the Gap with Generative Intelligence
When creating intelligence, it is clear that some of the data we need will be available using historical information or big data. But some data will be missing because the event has not yet happened and can only be revealed under certain conditions. To expose the missing data, we must use emulation to reproduce the mechanics of various forward-looking scenarios and examine the potential outcomes.
We currently believe perturbation theory may provide the best fit solution to escape the current limits of artificial intelligence and allow us to recover the unknown. Our mathematical emulation uses perturbation theory to not only accurately represent system dynamics and predict limits/singularities, but also reverse engineer a situation to provide prescriptive support for risk avoidance.
We have successfully applied perturbation theory across a diverse range of cases from economic, healthcare, and corporate management modeling to industry transformation and information technology optimization. In each case, we were able to determine with sufficient accuracy the singularity point—beyond which dynamic complexity would become predominant and the predictability of the system would become .
Our approach computes three metrics of dynamic complexity and determines the component, link, or pattern that will cause a singularity. It also allows users (humans or machines) to build scenarios to fix, optimize, or push further the singularity point.
Using situational data revealed by the predictive platform, it then becomes possible to create a new class of artificial intelligence, which we call generative intelligence. The goal of generative intelligence is to identify new cases before they occur and determine the appropriate response. These cases are unknowns in statistical methods, which are limited to prediction based on data collected through experience.
A diagnosis definition and remediation that covers both the experience-based knowns and those that were previously unknown can be stored together to allow for the rapid identification of a potential risk with immediate analysis of root causes and proposed remedial actions. A continuous enrichment of case-based knowledge will lead to new systems with the intelligence necessary to outperform any system which is reliant on only the original sources of known, experience-based data.
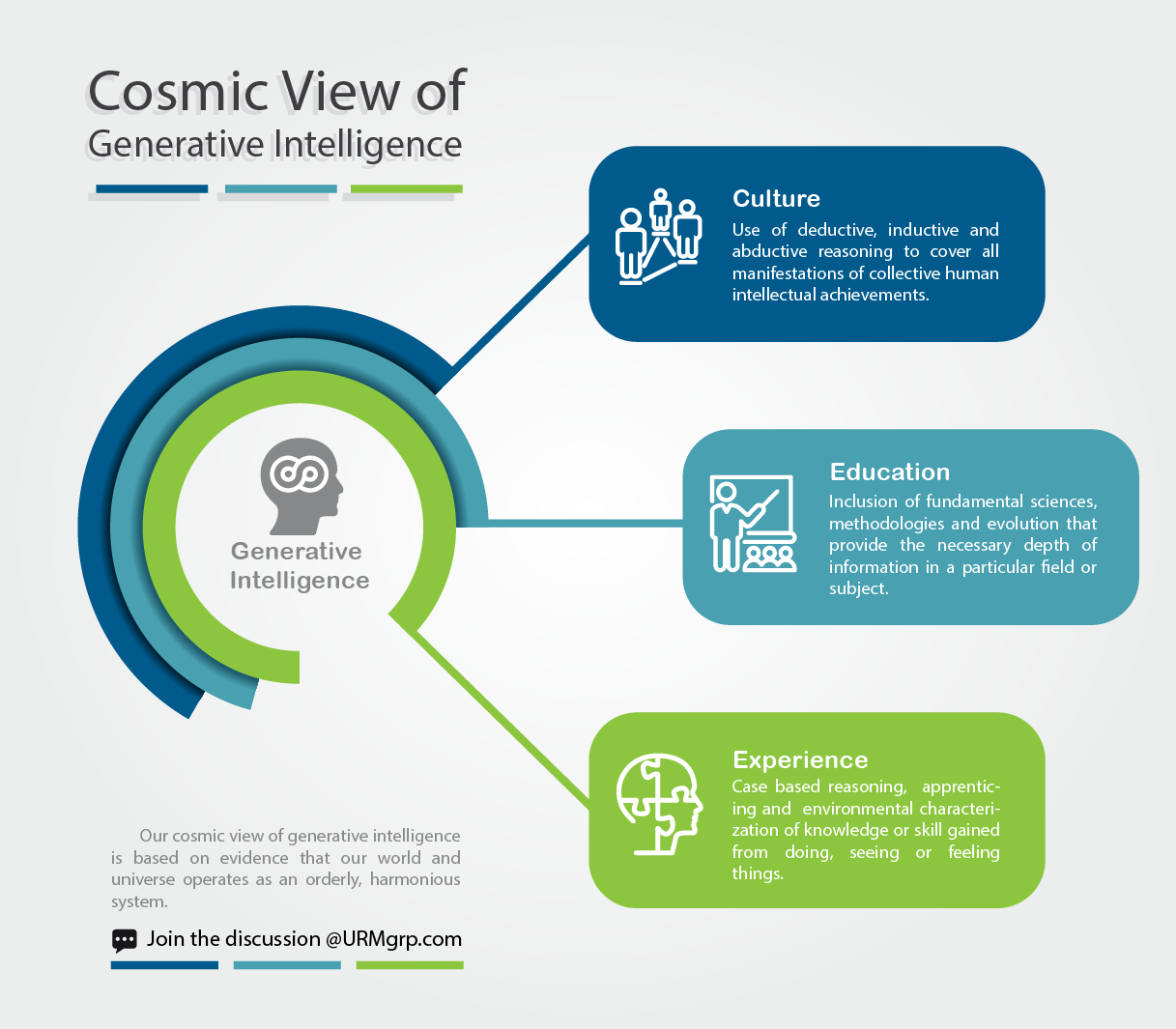
The Cosmic View of Generative Intelligence
We believe systems are deterministic, meaning that their future dynamics are fully defined by their initial conditions and therefore become fully predictable, with no random elements involved. To fully usher in a new era of intelligence and automation, a new culture must be established that will allow machines to extract the knowns but additionally grant them the ability to identify the unknowns.
The only way to achieve this goal is to build machines that are capable of determining the interdependencies and dynamic characteristics that will build gradually, exposing the limitation and identifying the critical zone where dynamic complexity predominates. Through this shift, machines can become adept in employing predictive capabilities to find the weak node of a complex chain through proper sensitivity and stress analysis.
Implementing Generative Intelligence
To accomplish our goal, we must identify all influencing forces. The small influences (considered as outliers by most of today’s popular actual analysis methods) are normally ignored in statistical methods or partial views built from big data relying on past experience that does not necessarily contain the data of attributes, behaviors or situations that have not happened yet. Perturbation theory deals with such attributes and behavior where small divisors and direct and indirect perturbations are involved in the computation regardless of their amplitudes so that all influencing forces are measured and understood. It also enables us to discover situations and predict.
We must also acknowledge outside influencers. The world is open, not in equilibrium, and the Piketty effect[3] adds polarizing forces that make it difficult to derive a conclusion through simple extrapolation. The emulation approach we use computes each prediction based on the parameters involved in the expression of dynamic complexity regardless of the past experience or past collected big data and therefore will produce projections independent from the analytical conditions an approach may impose—closed vs. open, or equilibrium vs. reactive/deterministic.
In this way, generative intelligence can be constructed based on a mix human experience, algorithms, observations, deductive paradigms and long range discoveries and notions that were previously considered external such as perception, risk, non-functional requirements (NFRs) and cost vs. benefits. Additionally, the sophistication of intelligence will independently evolve through a continuous process of renewal, adaption, and enrichment.
Managing the Move to the Cognitive Era
We see generative intelligence as the synthesis for the human progress. It escapes the taboos and congestion caused by past artificial intelligence philosophies and frees the human potential by using rational and unbiased mechanisms to harness the technological advances of the Fourth Industrial Revolution to create intelligent machine systems capable of predicatively, self-diagnosing problems and preventively, applying self-healing actions. In the simplest of terms, generative intelligence is able to continuously evolve by adding new intelligence that may not have been obvious at the outset.
Accomplishing such an ambitious goal will require new education and training, as well as a transfer of knowhow and scientific foundations. Additionally, we must anticipate the possible repercussions and enforce the ethics necessary to manage labor, inequality, humanity, security and other related risks. This level of technological progress has the potential to benefit all of humanity, but only if we implement it responsibly.
[1] Backprop or Backpropagation, short for “backward propagation of errors,” is an algorithm for supervised learning of artificial neural networks using gradient descent. Given an artificial neural network and an error function, the method calculates the gradient of the error function with respect to the neural network’s weights. It is a generalization of the delta rule for perceptrons to multilayer feedforward neural networks.
[2] We restrict our use of the term singularity to the one that defines the mathematical singularity as a point at which a given mathematical object is not defined or not well behaved, for example infinite or not differentiable.
[3] Piketty, Thomas. Capital in the 21st Century. Trans. Arthur Goldhammer. N.p.: Harvard UP, 2014. Print.